In one of our previous articles, we discussed how various support ticket classifications can be implemented in our help desk software for customer service and support. We’ve received a lot of feedback and comments from different people who are closely related to this issue, but also from people from other domains. For example, we’ve received comments and inquiries from software designers and developers, people from quality assurance, team leaders, and from end users of other similar systems. The comments were very interesting and sometimes started a long-term discussion.
Service request management
What we have learned from this information is that people understand the general classifications of service requests very differently and also handle them in very different ways. In addition, we learned that this question is much more complex than it appears at first glance, and the reasons are various. The most important is the environment and the domain from which it is observed and where the service management is performed. That’s why we decided to further clarify the reason why we decided to take this kind of solution in our customer support system.
To fully clarify these issues, we want to start from the basic requirements, such as the classification of different problems and requests in general. Afterward, we will explain how they can be classified in help desk software, along with their implementation.
The main requirement for recording support requests and the related support ticket is the proper description of the request. The description contains several different attributes, as well as the free-form text. It is later used in the help desk workflow to solve the problem effectively and to satisfy all relevant stakeholders: customers, developers, and end users.
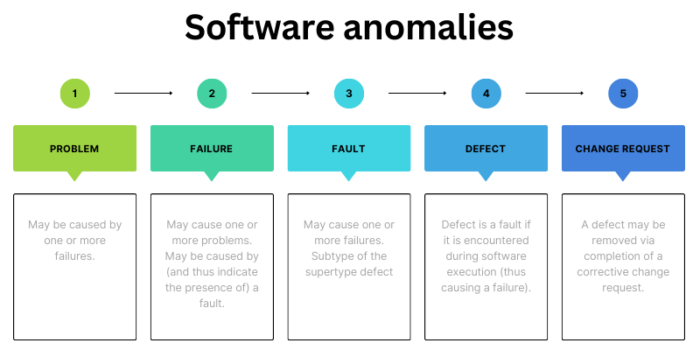
Most of the people from the support or maintenance area belong to software development. They are software engineers by profession who know their work very well and they feel how important is the classification of software failures and defects. They’ve learned to work with several classic schemes. One of the usually presented schemes is related to software problems, defects, and failures.
Problems, software failures, and defects
The most widely used classification schemes is the IEEE – 1044-2009 Standard Classification for Software Anomalies. In this document, the classification scheme with the core set of attributes is precisely presented. It can be used in almost any software environment and the choice of the life cycle model.
The classification scheme mainly considers software defects and software failures, although the following terms are also recognized and considered: problem, error, and fault. For example, software defects are described with 18 attributes, while failures are described with 20 attributes. Their common attributes are ID, status, description, etc.
The description of all attributes and their values requires a broad analysis, which is out of the scope of this article. It can be concluded that each attribute has its purpose within the life cycle model or help desk practices. However, in the help desk environment where customer support is performed, we distinguish the following main activities within the workflow:
- Initial investigation and diagnosis: the primary classification is performed to enable initial evaluation, that follows acceptance or rejection.
- Assignment: routing to the appropriate person or organization within a maintenance or development team for further actions.
- Analytic reporting: providing customer support metrics needed for software process improvement (team efficiency, help desk load, SLA performance, software quality assurance), customer billing for maintenance services, etc.
Having a restricted set of activities compared to the entire life cycle model, the number of attributes can be consequently restricted. In the following lists, the main attributes required for the main activities are presented.
The main attributes for software defects are:
- Asset: Product (Product A, Product B, …), Component (C1, C2, …), Module (M1, M2, …), etc.
- Priority: Low, Medium, High. The “Urgent” is also added in some of the implementations.
- Severity: Trivial (Inconsequential), Minor, Major, Critical
- Effect: Functionality, Usability, Security, Performance, Serviceability, Other
- Type: Data, Interface, Logic, Description, Syntax, Standard, Other
- Mode: Wrong, Missing, Extra
- Insertion activity: Requirements, Design, Coding, Configuration, Configuration
- Detection activity: Requirements, Design, Coding, Supplier testing, Customer testing, Production, Audit, Other.
Similar to defects, the main attributes of software failures are:
- Environment: webserver1, webserver2, dbserver1, …
- Configuration: cfg-A.1, cfg-B.9, …
- Disposition: Cause unknown, Duplicate, Resolved
- Severity: same as in the software defects.
Note that sample values are informative, which is also clearly noted in the standard, and that each organization can adjust or record its values.
We can agree that this classification supports the complete workflow in a typical software lifecycle when it comes to software defects and failures. However, although the IEEE classification is very clear and precise, its implementation and proper use within a development organization remain very complex. This is particularly relevant to small and agile teams that usually do not have a dedicated staff in charge of the classification process. The activities that need to be performed in the process require a certain amount of time and other resources, which everything slows down and burdens the entire help desk workflow.
Data acquisition and recording
One of the main problems in the implementation of this or a similar classification scheme is the question of who is responsible for recording and maintaining this data in an organization. When considering the effort required to solve the reported problem itself, whether it is a defect or failure, there is more or less agreement that developers or maintenance personnel should be responsible for the data acquisition and recording.
The prerequisite for solving a problem is that a high-quality identification of the cause of the problem has been previously carried out, which follows the classification so that proper assignment can be performed. On the other hand, to carry out the classification, it is necessary to have a broad knowledge of the complete software system, which again points to an experienced software designer or at least a software developer.
As a consequence of problems with the initial classification of support requests and problems, the two most common errors occur when collecting and recording problems in a typical help desk software. These errors are even visible in high-quality and expensive solutions:
1. Provision of submission forms for software problems and tickets with attributes related to software defects.
At first glance, all listed attributes make sense in describing software incidents or problems reported by customers. However, software defects are related to any work product from the life cycle, which includes software documentation, software code, modules, libraries, and other artifacts. In this way, the support system or help desk software is unnecessarily burdened with data that is difficult to enter and maintain, which additionally increases the workload of the support and maintenance team.
2. The customer is expected to perform the classification.
Once a ticket submission form is created containing a large number of attributes, the following mistake is usually made by asking the customer to perform a classification of their request, partial or even complete. A typical example is the formation of a hierarchical scheme with a main category and a subcategory as follows:
| Main Category | Subcategory |
| Software | Application Operating system DBMS |
| Hardware | Memory Disk CPU Keyboard |
| Network | IP address DHCP DNS Wi-Fi |
At first glance, this kind of hierarchical scheme is clear and rational. It can also be assumed that the intention of the organization that creates this scheme is the assignment of created support requests and tickets, and later for generating various analytical reports.
However, presenting this scheme to the customer may cause additional problems. We can imagine a customer who fills out a submission form, and who previously experienced a failure in the software system. For example, the customer experiences non-responsive software during manipulation at some point in time, and lost the ability to manipulate the software – “locked screen”. After that, the customer should report the problem and perform the correct classification. One can ask: “Is the problem in software, hardware, or maybe network?”. Let’s say he chooses the hardware, then he will be asked again whether the cause of the problem is his IP address, DHCP, etc.
Even if a typical customer had sufficient technical knowledge, we can expect that the problem is the result of several causes, e.g. memory + DHCP + application, which does not help in the actual classification. On the other side, when the customer does not have enough technical knowledge, then the probability of correct classification tends to be zero. In both cases, this kind of initial classification is very annoying for customers and increases user dissatisfaction.
In the next article, we’ll explain the classification of general customer requests, as well as the difference compared to the classification of software problems.